
Terminology
Scaling (IT) — the process of adjusting the resources of a computing system to meet changing demands for data processing and service delivery.
Autoscaling (IT) — the process of dynamically allocating resources based on the system’s performance requirements.
Vertical scaling — increasing the performance of each system component to improve overall performance.
Horizontal scaling — the process of increasing system computing capacity by adding new servers (nodes) to the infrastructure.
Replication (DB) — the process of copying data from one database server (primary) to other servers (replicas) to ensure availability, fault tolerance, and improved performance.
Clustering — the process of combining multiple servers or nodes into a single system (cluster) so they work together to provide high availability, fault tolerance, and scalability. Replication can be part of clustering, but a cluster as a whole includes a broader range of capabilities and functions for load management, ensuring high availability and fault tolerance.
Federation — an approach for working with independent systems, where each system can use its own technologies and manage its own data, providing flexibility and integration capabilities. Interaction between systems is carried out through standardized communication methods such as REST API, gRPC, or message queues.
Partitioning — the process of dividing data within a database or storage system into smaller, manageable parts called partitions.
Load balancer — a component of the network infrastructure that distributes incoming traffic or requests across multiple servers or resources to optimize performance, improve availability, and ensure fault tolerance.
Scaling
One of the key tasks of an IT specialist is to ensure the scalability of the infrastructure, allowing the system’s capacity and performance to be increased quickly and cost-effectively. This may include both increasing (scaling up) the computing power of individual components and adding new components (scaling out) to enhance the system’s performance and reliability.Let’s look at examples of scaling in different areas:
- Web applications: Scaling to handle peak loads during sales or marketing campaigns.
- Cloud services: Dynamic resource allocation depending on user demand.
- Games: Scaling game servers to support a large number of players simultaneously.
Advantages
- Improved performance: When system load increases, additional computing resources can be dynamically added, allowing more requests and data to be processed per unit of time. This is especially important for resource-intensive applications such as online games, e-commerce platforms, and analytics systems.
- Increased availability: By duplicating components and distributing the load across multiple servers, the risk of failures can be minimized, ensuring continuous system operation. This is particularly critical for services that businesses rely on, such as banking systems and production management systems.
- Cost optimization: Achieved through optimal resource usage. Scaling makes it possible to pay only for the computing power that is actually used at a given time. This is especially relevant for cloud services, where costs are based on actual resource consumption.
- Flexibility: The ability to quickly and easily adapt to changes in business processes and user requirements enables companies to respond faster to market changes and adopt new technologies.
Autoscaling
It would be ideal if a system could automatically increase or decrease the number of resources depending on the load. This brings us to automatic scaling. Indeed, as load grows, applications may require additional resources to maintain the necessary level of performance and to meet increasing demands. When the need for resources decreases, autoscaling helps reduce costs by releasing unused resources. This process takes advantage of the elasticity of cloud environments, simplifying system management and reducing the need for operators to constantly decide on adding or removing resources and monitoring performance. Vertical scaling is less commonly performed automatically, as it often requires temporary downtime for redeployment. In contrast, horizontal scaling is easier to automate: it involves adding or removing resource instances without interrupting the application. When the load decreases, excess resources can be seamlessly shut down and released without downtime. Many cloud providers support automatic horizontal scaling. Here are some popular solutions you can integrate with your website to implement autoscaling:- Amazon Web Services (AWS) Auto Scaling
- Microsoft Azure Autoscale
- Google Cloud Platform (GCP) Managed Instance Groups
- IBM Cloud
- Oracle Cloud
- Cloudways
- Kinsta
- Nexcess
- 20i Autoscale
- DigitalOcean App Platform
- platform.sh
Vertical scaling
 In the world of IT infrastructure, vertical scaling is the path chosen when the goal is to quickly boost system performance without introducing complex changes. Imagine the situation: your website or application starts slowing down, users complain about delays, and the server is increasingly hitting its limits. At that moment, the logical step seems to be simply upgrading the existing server — adding more RAM, a faster CPU, or additional disk space.
This approach often turns out to be a simple and effective solution: there’s no need to redesign the architecture, implement complex load distribution mechanisms, or manage an entire fleet of servers. All management and maintenance are concentrated in a single point, reducing administrative costs and speeding up the implementation of changes. For many companies, this is especially important when infrastructure development resources are limited and time is a critical factor.
However, behind this apparent simplicity lie certain limitations. Every server, no matter how powerful, has its physical limit. At some point, upgrading resources becomes either impossible or economically impractical. Moreover, the entire system depends on a single point of failure: if something happens to that server, the entire platform may become unavailable. This is especially critical for businesses where downtime is unacceptable. Another important factor is flexibility. Vertical scaling works well when load increases gradually and predictably. But if you face sudden traffic spikes or plan for rapid growth, this approach may fall short. The time required for upgrading or replacing a server can become critical, particularly for services that demand high availability.
The decision to move toward vertical scaling usually doesn’t come immediately but rather after certain warning signs begin to appear: the CPU is constantly overloaded, memory is insufficient, the database is slowing down, and users notice increased response times. If your application’s architecture does not allow it to be easily split into parts and the load distributed across multiple servers, vertical scaling becomes the most logical step. This is especially relevant for monolithic systems or cases where managing a single powerful machine is simpler and cheaper than building a complex distributed infrastructure.
In the world of IT infrastructure, vertical scaling is the path chosen when the goal is to quickly boost system performance without introducing complex changes. Imagine the situation: your website or application starts slowing down, users complain about delays, and the server is increasingly hitting its limits. At that moment, the logical step seems to be simply upgrading the existing server — adding more RAM, a faster CPU, or additional disk space.
This approach often turns out to be a simple and effective solution: there’s no need to redesign the architecture, implement complex load distribution mechanisms, or manage an entire fleet of servers. All management and maintenance are concentrated in a single point, reducing administrative costs and speeding up the implementation of changes. For many companies, this is especially important when infrastructure development resources are limited and time is a critical factor.
However, behind this apparent simplicity lie certain limitations. Every server, no matter how powerful, has its physical limit. At some point, upgrading resources becomes either impossible or economically impractical. Moreover, the entire system depends on a single point of failure: if something happens to that server, the entire platform may become unavailable. This is especially critical for businesses where downtime is unacceptable. Another important factor is flexibility. Vertical scaling works well when load increases gradually and predictably. But if you face sudden traffic spikes or plan for rapid growth, this approach may fall short. The time required for upgrading or replacing a server can become critical, particularly for services that demand high availability.
The decision to move toward vertical scaling usually doesn’t come immediately but rather after certain warning signs begin to appear: the CPU is constantly overloaded, memory is insufficient, the database is slowing down, and users notice increased response times. If your application’s architecture does not allow it to be easily split into parts and the load distributed across multiple servers, vertical scaling becomes the most logical step. This is especially relevant for monolithic systems or cases where managing a single powerful machine is simpler and cheaper than building a complex distributed infrastructure.
Early warning signs
- High CPU load: Constant CPU usage at 100% leads to request processing delays and lowers overall system performance.
- Insufficient RAM: When memory runs out, applications switch to using swap space, which significantly slows down their performance.
- Lack of disk space: When disk capacity is nearly full, the system cannot write new data, causing failures and potential application crashes.
- Increased response time: Noticeable growth in application response time is often linked to resource shortages and indicates the need for scaling.
- Database slowdown: With large volumes of data, the database may start processing queries more slowly. Vertical scaling helps improve performance by adding RAM and CPU power.
Horizontal scaling
When all optimization measures have been exhausted — caching is enabled, database indexes are configured, and the application’s code and architecture are optimized — the next step is horizontal scaling. Horizontal scaling allows the load to be distributed across multiple servers by adding new nodes to the system, providing higher resilience, improved performance, and the ability to handle more requests simultaneously, reducing the risk of overload and increasing availability. This approach is especially effective for large-scale applications with a growing number of users and requests, where increasing resources on a single server (vertical scaling) no longer yields the desired improvement.Early warning signs
Here are several indicators that it may be time to consider horizontal scaling:
- Performance issues: If your servers are starting to experience high load and application response times increase, this is a clear signal to scale.
- Data growth: If the volume of data in your database grows rapidly and current systems cannot handle query processing efficiently, this is another reason to consider horizontal scaling.
- Increasing number of users: If the number of users or active sessions increases and begins to affect performance, it may be necessary to distribute the load across multiple servers.
- Frequent failures and overloads: If servers frequently crash or become unavailable due to overload, this can also indicate the need for scaling.
- Slow database queries: If already optimized queries are still running slowly, this is a serious sign that the architecture needs to be optimized.
Application Scaling
When designing and deploying scalable applications, the load balancer plays a key role. This component is responsible for distributing incoming traffic across multiple servers, ensuring high availability and optimal system performance.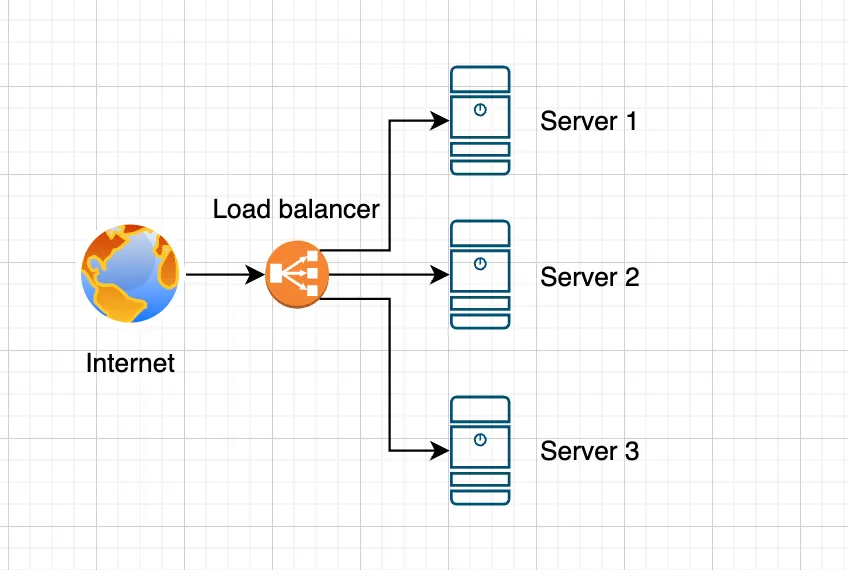 A load balancer receives incoming requests from clients and determines which server among the available ones should handle each request. The load distribution process can be based on various algorithms, such as:
A load balancer receives incoming requests from clients and determines which server among the available ones should handle each request. The load distribution process can be based on various algorithms, such as:
- Round Robin: Requests are sent sequentially to each server in the cluster.
- Least Connections: A request is directed to the server with the fewest active connections, helping to avoid overload.
- IP Hashing: Requests are distributed based on the client’s IP address, which helps maintain session consistency.
- Random: Requests are sent to a random server, which can be useful for evenly distributing load.
Sticky sessions
It is possible to configure a load balancer to send the same user to the same server, and the method chosen depends on your system requirements and architecture:- Using cookies: On the client’s first request, the load balancer sets a cookie indicating which server the user was directed to. For subsequent requests, the load balancer checks for this cookie and routes the requests to the same server.
- Using IP address: Binding sessions based on the client’s IP address. The load balancer will send all requests from the same IP to the same server. Has limitations with NAT/proxy.
- Nginx settings: If you are using Nginx as a load balancer, sticky sessions can be enabled using the ngx_http_upstream_module.
Shared session
User state can be stored in server memory. However, this may cause problems if a server fails or is replaced. In such cases, mechanisms for backing up the state must be provided. To increase resilience, external data storage systems such as databases, Redis, or Memcached can be used. This allows user states to be stored in a centralized location accessible to all servers. Thus, regardless of which server handles a request, the user’s state can always be restored.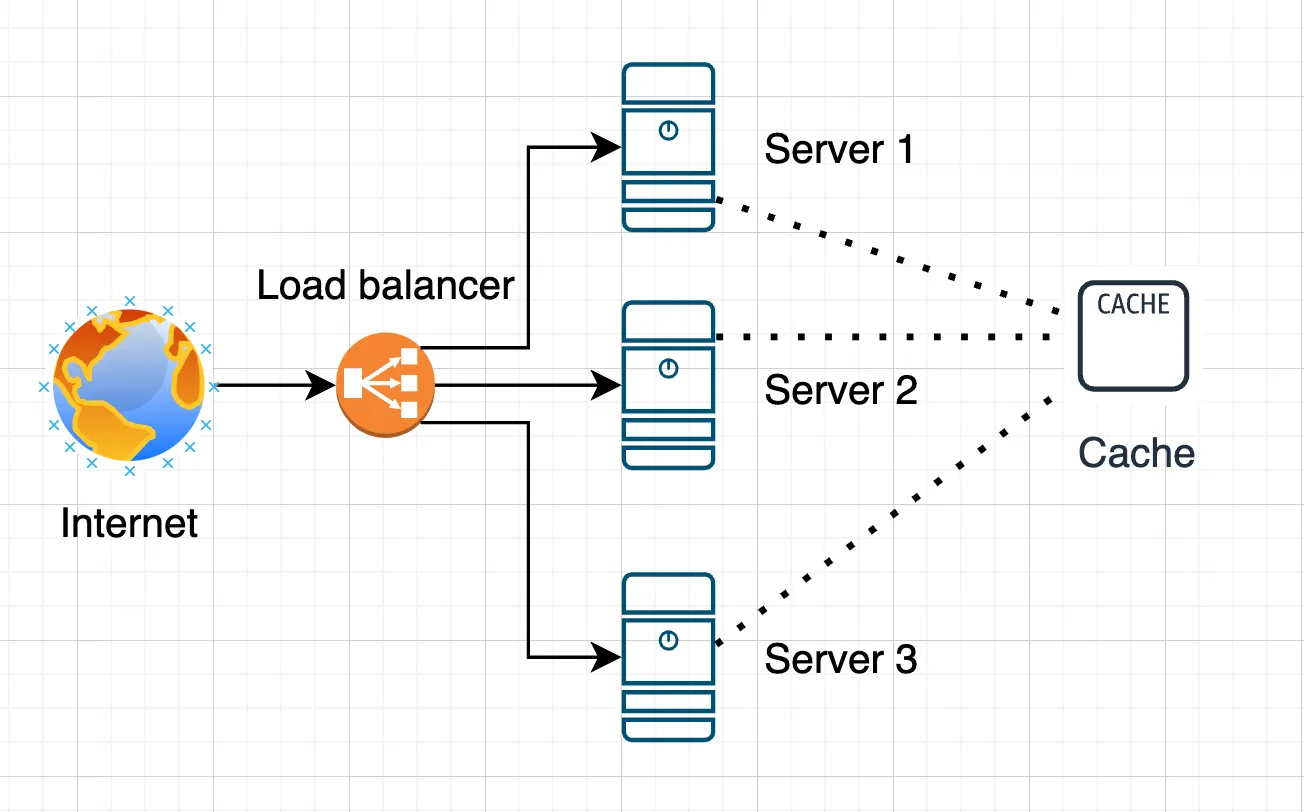
Memcached Scaling
Memcached supports horizontal scaling — adding new servers to distribute data and load among them. Data is distributed using key hashing, so when the number of servers increases, the cache is recalculated and data may move to other nodes. Memcached does not support automatic data distribution across servers. Sharding is performed on the client side, where the client library determines which server stores the data for each key. When servers are added or removed, the hashes for all keys must be recalculated, which can lead to cache “misses.”Redis Scaling
Redis does not support automatic sharding out of the box, but data can be manually distributed across multiple Redis instances. Keys are divided among different servers using hashing or another method of key distribution. For example, with Redis Cluster, data can be distributed across nodes and managed automatically. Redis Cluster is a built-in Redis feature that automates data distribution and supports horizontal scaling. It creates groups of nodes, distributes data among them, and automatically performs replication to ensure fault tolerance. If a node fails, the cluster redirects requests to other nodes.Replicating files between servers
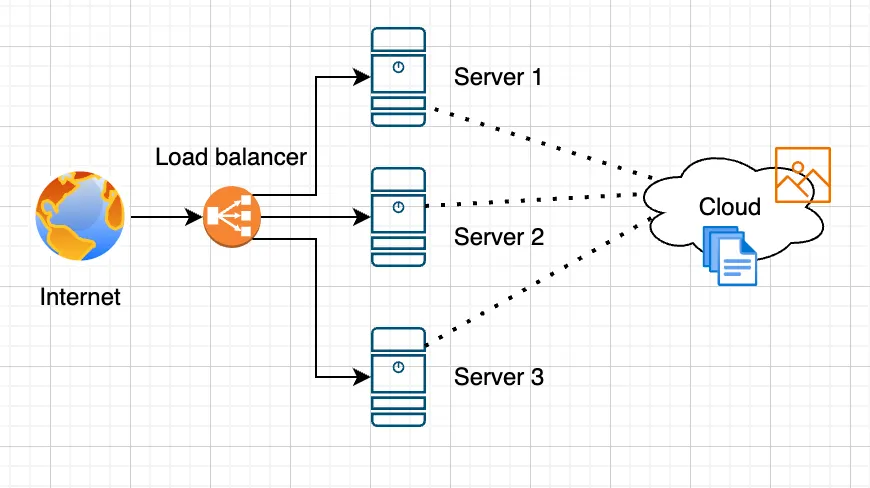
Let’s make our application more complex and add the ability to upload files and photos. To ensure access to user-uploaded files across all servers in our load-balanced architecture, we can consider several approaches. The most obvious and straightforward method is to set up replication of uploaded files between all servers. This can be done using tools like rsync, GlusterFS, or other file synchronization solutions.Advantages
- Each server stores local copies of files, which can provide faster access.
- Performance can improve due to quick access to cached data.
Disadvantages
- The architecture becomes more complex.
- It requires monitoring the synchronization state of files.
- You need to manage caching and cache invalidation.
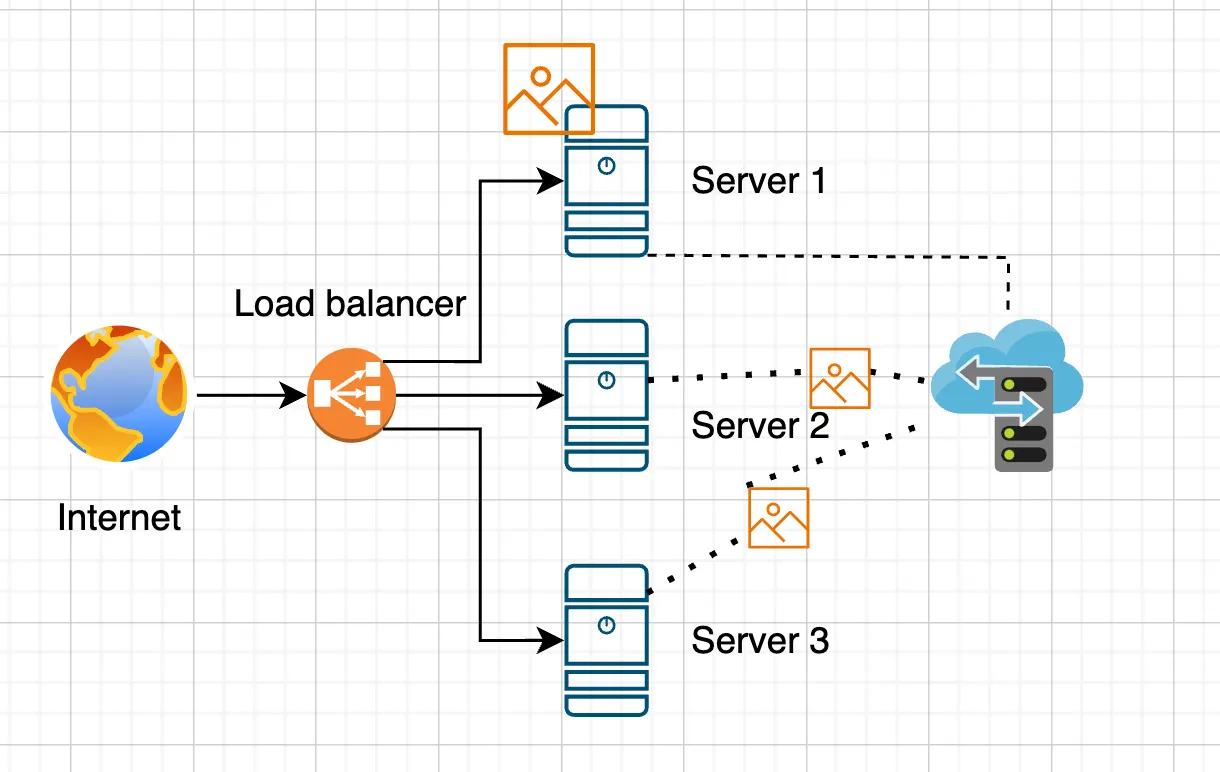
Caching uploaded files
You can use a cache to store uploaded files. For example, after uploading, files can be cached in Redis or Memcached, and then when requested, the system checks whether the file is in the cache. However, the most common and reliable method is to use a shared storage accessible by all servers.Shared storage
This can be a network-attached storage (NAS), cloud storage (such as Amazon S3 or Google Cloud Storage), or a network-accessible file system (NFS).Advantages
- Easy to manage and access files.
- Supports automatic backups and scaling.
Disadvantages
- Additional latency when accessing network resources.
Database scaling
To make our project more complex, we will add a database (DB) that will serve as the primary storage for the application’s data. This will allow us to manage data more efficiently, ensure long-term storage, and perform more complex queries.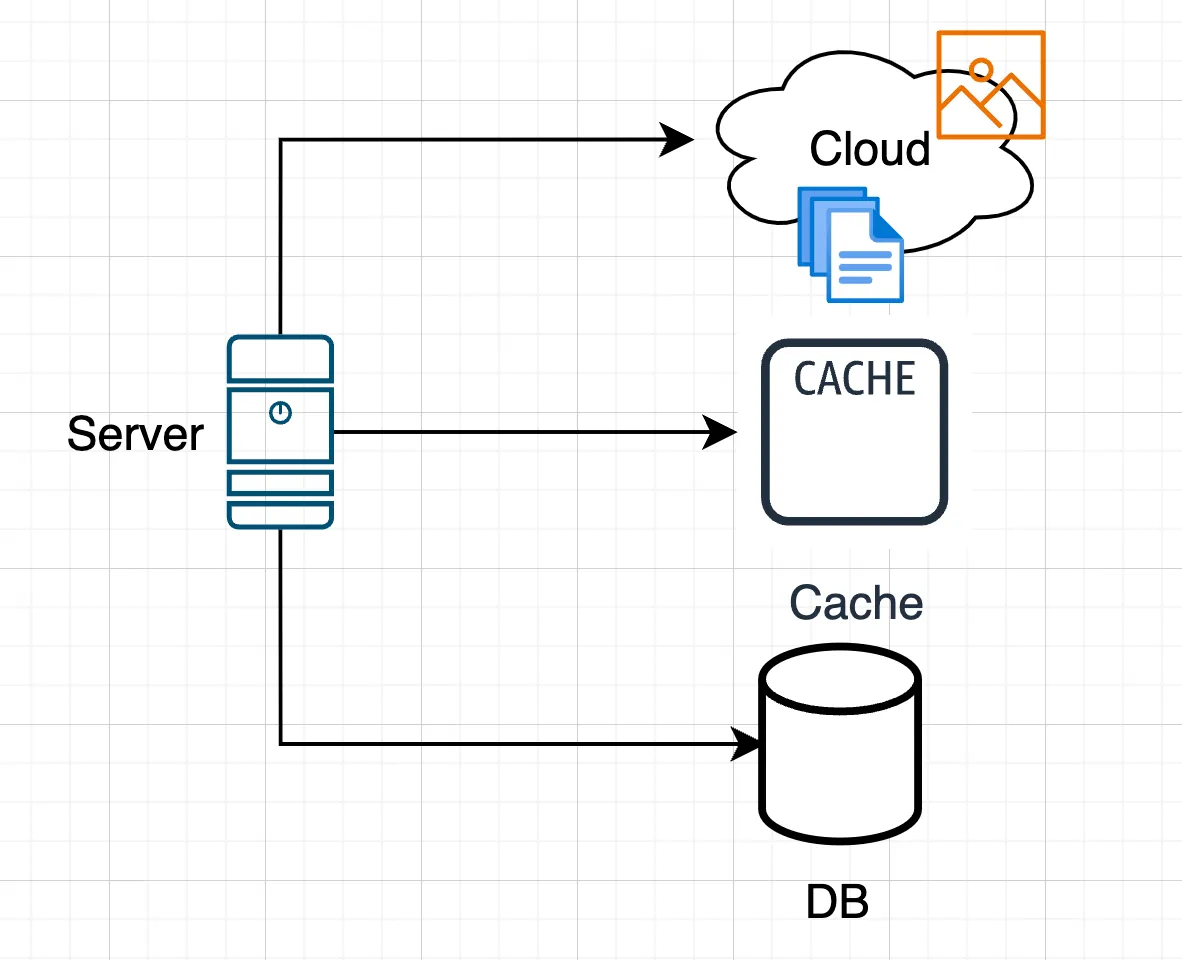 There are three approaches to organizing a database when scaling servers:
There are three approaches to organizing a database when scaling servers:
- Single shared database for all servers. All application servers connect to a single database. This simplifies data management and maintains data integrity but increases the load on a single database server, which can become a bottleneck under high traffic.
- Separate databases on each server. Each application server is assigned its own database. This approach reduces the load on individual nodes and allows servers to operate independently, but it complicates data consistency and synchronization between servers.
- Sharding. Data is distributed across multiple servers using sharding, where each server (or shard) stores only a portion of the data. This reduces the load on each server and increases overall capacity, allowing the database to scale horizontally.
One common database for all servers
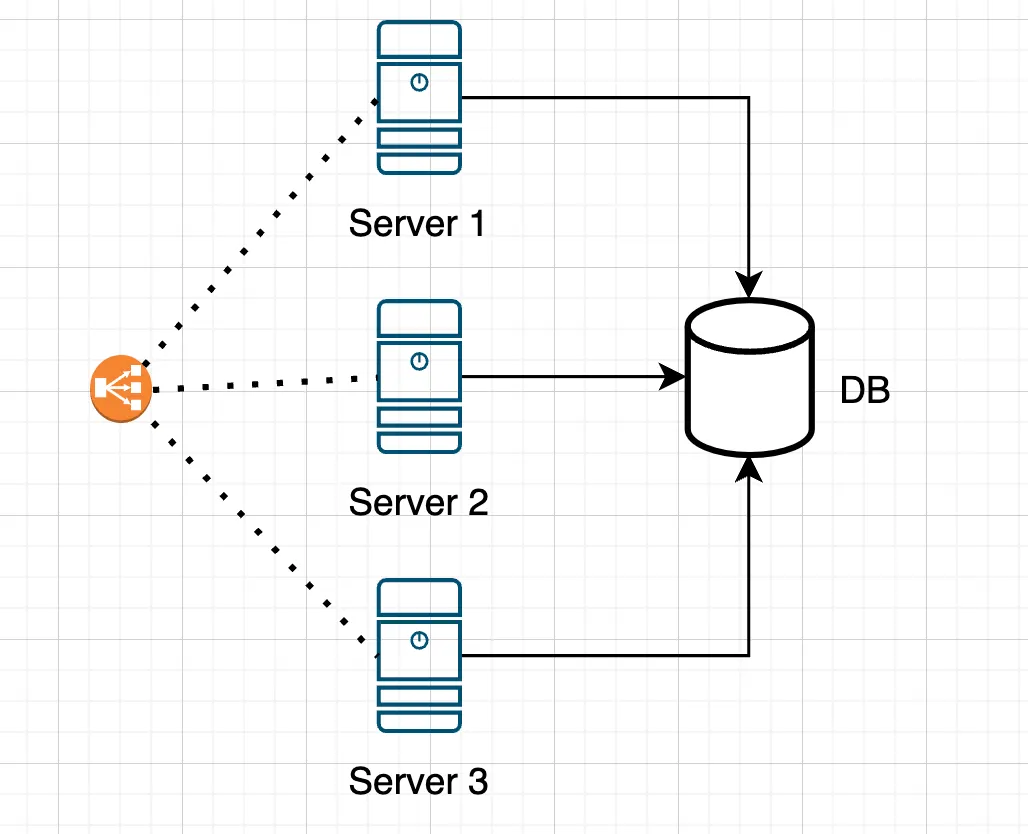 If your application does not expect high traffic, and simplicity, data integrity, and the ability to perform complex queries are important, it makes sense to start with a single shared database. This simplifies data management, avoids synchronization issues, and allows you to focus on developing the application’s functionality.
If your application does not expect high traffic, and simplicity, data integrity, and the ability to perform complex queries are important, it makes sense to start with a single shared database. This simplifies data management, avoids synchronization issues, and allows you to focus on developing the application’s functionality.
Advantages
- Simplified data management since all data is in one place.
- Easy backup and restore procedures.
- No need to synchronize multiple databases.
Disadvantages
- Potential performance issues under high load, as all requests are directed to a single database.
- Limited availability: if the database fails, all servers lose access to the data.
To prevent a single database from becoming a bottleneck, architectural approaches such as replication or clustering can help distribute the load.
What to choose?
Replication is suitable for simple applications or those where read performance is critical. In this case, a master-slave setup is usually sufficient.
Clustering is suitable for high-load projects, providing high availability and scalability by distributing the load across multiple nodes. Start with simple replication and carefully monitor the load to identify bottlenecks. Scale the system as needs grow.
Choose replication if:
- Read/Write ratio > 80/20 — low write operations
- Fault tolerance is required (having a copy of the data)
- Read load distribution is needed
- Real-time backup is required
- Reducing latency for geographically distributed users
- Budget is limited (simpler to set up and maintain)
Choose clustering if:
- Read/Write ratio is closer to 50/50 or there are many write operations
- Large volumes of data need processing
- Load distribution is needed for both reads and writes
- Automatic sharding is required
- High availability with automatic recovery is needed
Separate databases on each server
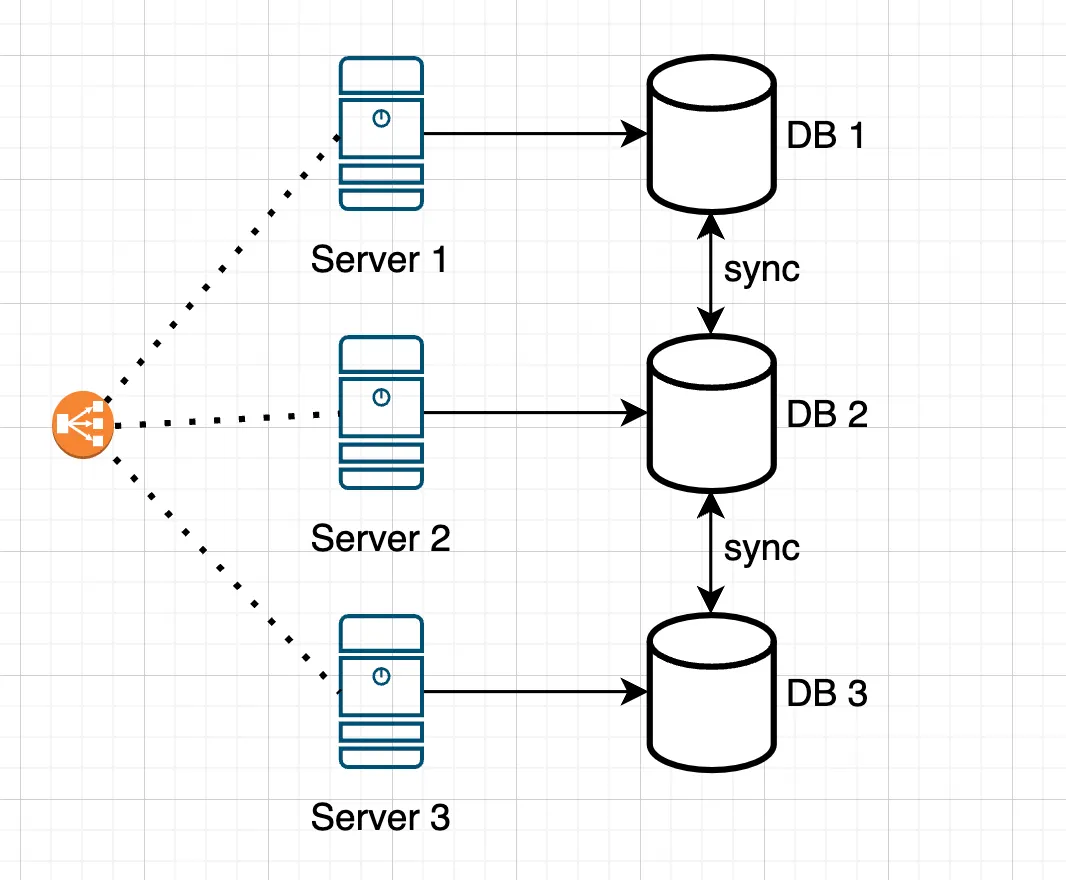 If the application does not require frequent data exchange between nodes and can operate in a “local data” mode, it is more practical to use separate databases.
You will also need to manage individual database instances on each server if you are using one of the following DBs: Microsoft Access, SQLite, FileMaker, Berkeley DB, DBase, H2 Database.
If the application does not require frequent data exchange between nodes and can operate in a “local data” mode, it is more practical to use separate databases.
You will also need to manage individual database instances on each server if you are using one of the following DBs: Microsoft Access, SQLite, FileMaker, Berkeley DB, DBase, H2 Database.
Advantages
- Higher availability and fault tolerance: if one database fails, the others can continue operating.
- Load distribution, as each server can handle requests to its own database.
Disadvantages
- Data synchronization between databases is complex if consistency is required.
- More complex management and backup, since multiple databases must be monitored.
- Set up replication between databases.
- Use a messaging system such as RabbitMQ or Apache Kafka. When data changes on one node, send a message to a queue, which other nodes process to update their databases.
- Create a centralized API responsible for managing data.
- Use periodic synchronization scripts if data changes infrequently.
Sharding
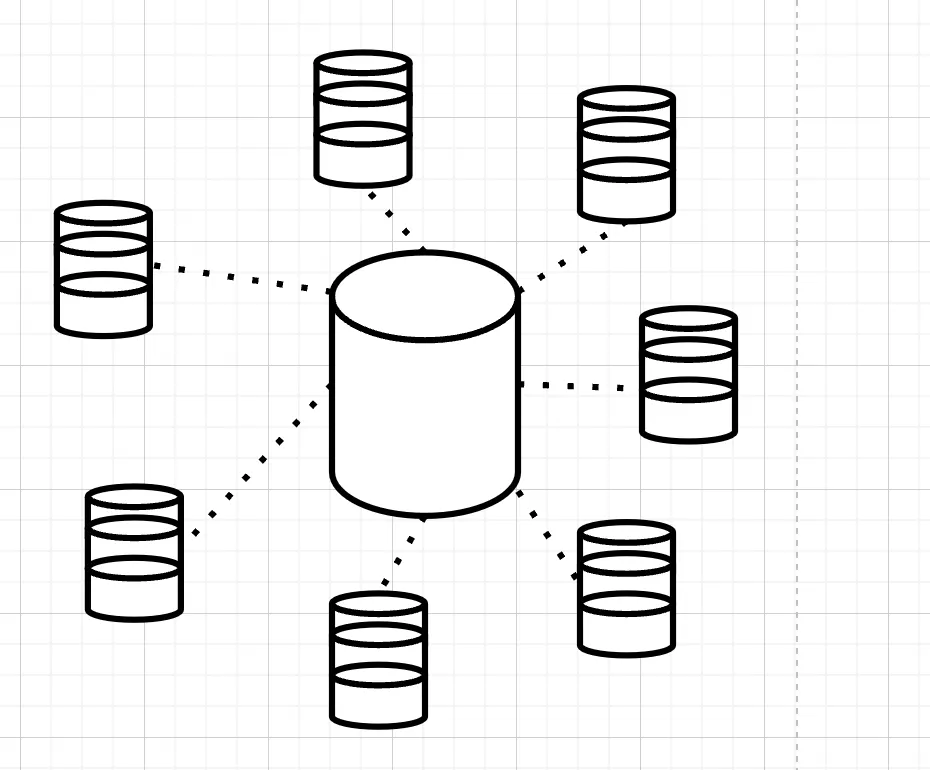 Although sharding adds some complexity to the architecture, the performance and scalability benefits make it the best choice for high-load applications with multiple services.
The first step is to choose a sharding strategy, which determines how data will be distributed across different database instances. This can be based on various criteria, such as users, regions, or data types. For example, you could distribute users across different databases depending on their geographic location, which helps improve performance and reduce latency.
After defining the sharding strategy, it is necessary to implement query routing logic. This involves developing a mechanism that directs requests to the appropriate sharded database instance based on query parameters. Proper routing setup is critical to ensure fast query processing and minimize response times.
Finally, it is important to set up monitoring and management for the sharded databases. You need a system that tracks the performance and load of each sharded instance. This helps identify bottlenecks early, analyze resource usage, and take measures to optimize system performance.
Although sharding adds some complexity to the architecture, the performance and scalability benefits make it the best choice for high-load applications with multiple services.
The first step is to choose a sharding strategy, which determines how data will be distributed across different database instances. This can be based on various criteria, such as users, regions, or data types. For example, you could distribute users across different databases depending on their geographic location, which helps improve performance and reduce latency.
After defining the sharding strategy, it is necessary to implement query routing logic. This involves developing a mechanism that directs requests to the appropriate sharded database instance based on query parameters. Proper routing setup is critical to ensure fast query processing and minimize response times.
Finally, it is important to set up monitoring and management for the sharded databases. You need a system that tracks the performance and load of each sharded instance. This helps identify bottlenecks early, analyze resource usage, and take measures to optimize system performance.
Scaling ElasticSearch
Let’s add ElasticSearch to our application to search and analyze large amounts of data in real time. ElasticSearch supports both replication and sharding.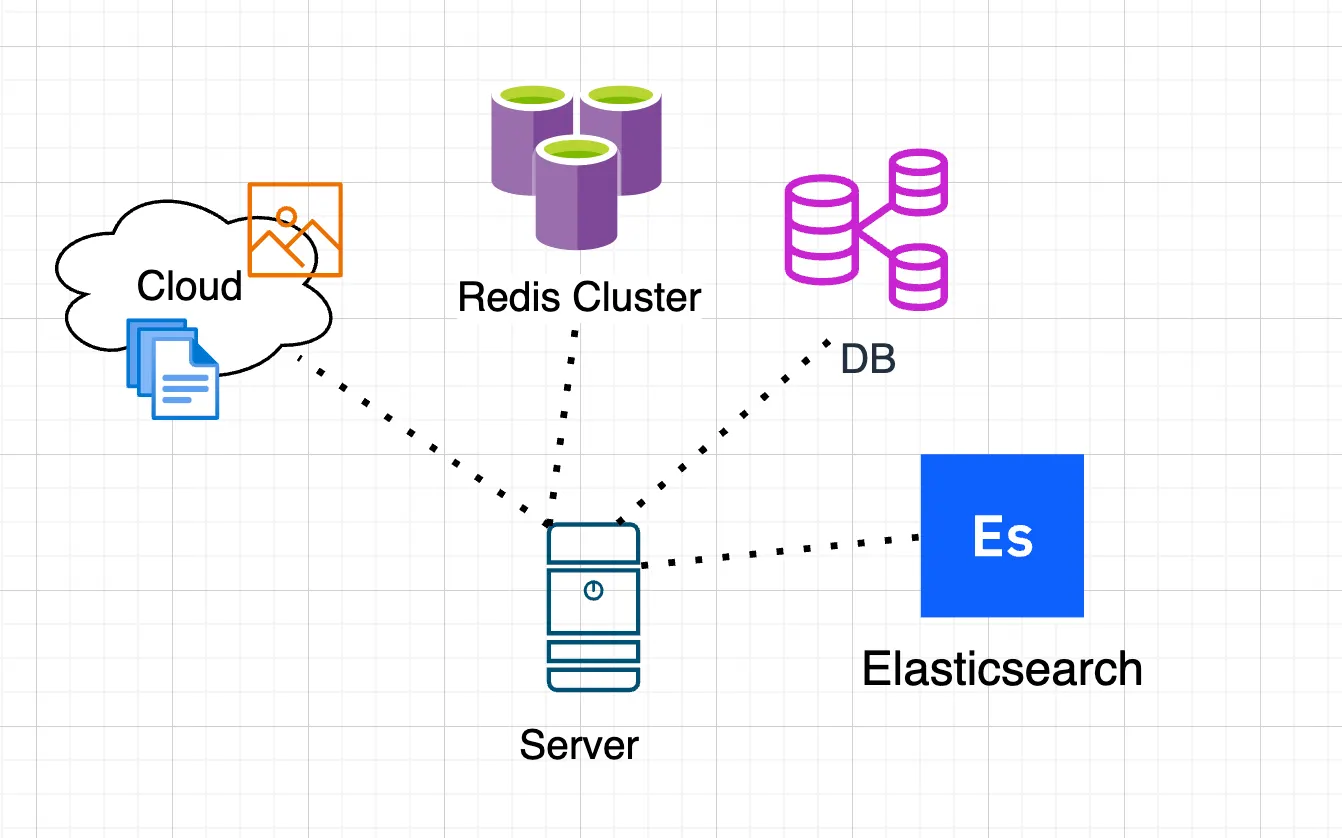
Sharding and Replication in Elasticsearch
Sharding in Elasticsearch is a mechanism that splits an index into smaller parts called shards, which are distributed across cluster nodes for efficient handling of large volumes of data and system scalability. Sharding improves performance by allowing each node to handle only a portion of the data, speeding up queries and indexing. It also enables horizontal scaling, as new nodes can be added to distribute the load, and parallel query processing across shards reduces response times. However, configuring the optimal number of shards requires careful planning, as improper settings can degrade performance. Rebalancing shards when adding or removing nodes can be resource-intensive and temporarily impact system operation. Additionally, changing the number of primary shards after index creation requires reindexing, which is costly for large datasets. Replication in Elasticsearch creates copies of shards, placed on different nodes to enhance data reliability and availability. Replicas protect data in case of node failures, minimize the risk of data loss, and allow read requests to be distributed between primary shards and their replicas, reducing load on individual nodes and speeding up processing. Replicas can also be placed in different data centers to improve accessibility. However, each replica increases storage requirements, and synchronizing data between primary shards and replicas can introduce delays or additional load, especially during frequent write operations. Network failures or synchronization delays can sometimes cause temporary data inconsistencies. Combining sharding and replication in Elasticsearch allows both scalability and fault tolerance. Sharding distributes data and load, while replication ensures reliability and speeds up reads. Each index is split into primary shards, for which replicas are created, maintaining a balance between performance and data availability. For optimal system performance, it is important to configure the number of shards and replicas correctly. Too many shards increase overhead, while too few can overload nodes. The optimal shard size is usually 20–50 GB, depending on the data and load. Typically, one or two replicas per shard are sufficient to balance reliability and storage costs. Regular monitoring via Elasticsearch tools such as Kibana or the cluster API helps track performance and shard distribution, avoiding uneven load or “hot” nodes. Planning scaling in advance minimizes the impact of shard reallocation on system operation.Scaling RabbitMQ
RabbitMQ allows adding additional nodes to a cluster to increase throughput and system reliability. Multiple RabbitMQ nodes in a cluster can process messages together, sharing the load and ensuring high availability. Each node in the cluster maintains data for its own queues, while messages are distributed among the nodes.Scaling Methods
- Clustering: Combining multiple nodes into a single logical broker.
- Federation: Asynchronous message transfer between brokers.
- Sharding: Distributing queues across nodes.
Which to choose?
- Clustering: Best for high availability, reliability, and ease of management.
- Sharding: Ideal for increasing performance and handling large message volumes. Suitable for scenarios requiring high parallel processing.
- Federation: Suitable for distributed architectures where different parts of the system are in different geographic locations. It allows servers to remain independent while minimizing network latency and issues.
framework:
messenger:
transports:
shard1:
dsn: 'amqp://user:password@host:port/vhost/shard1'
shard2:
dsn: 'amqp://user:password@host:port/vhost/shard2'
routing:
'App\Message\YourMessage': shard1
'App\Message\AnotherMessage': shard2
Kafka Scaling
Apache Kafka allows adding additional brokers to a cluster to increase performance, reliability, and fault tolerance. Kafka supports horizontal scaling at the broker, partition, and topic levels, making it particularly suitable for handling large volumes of real-time data. Kafka provides partitioning — splitting data within a topic into multiple partitions, which can be distributed across different brokers — and replication — creating copies of partitions on different brokers to improve reliability and availability.Which to choose?
- For high-volume streaming data: If you expect large data flows and heavy load, use partitioning and add brokers simultaneously. This maximizes performance and flexibility.
- For mission-critical systems: If data availability and fault tolerance are priorities, configure replication of partitions across multiple brokers to ensure reliability.
Stress Testing
Today, there are many tools available that simulate a large number of users — essentially “flooding” the server with requests — to test its resilience and determine how stably it handles high load. These tools generate intensive traffic on the target server, sending numerous requests to various resources, which helps identify weak points in the system architecture. When developing web services and applications, it’s important to understand the limits of the system. Load-testing utilities allow developers and administrators to assess server performance under heavy activity. This enables preparing the system for traffic growth, improving request handling, and avoiding downtime. A good reference on this topic is an article by Alexander Makarov (SamDark).Popular Tools
- Apache JMeter: Allows creating and sending requests to web servers, simulating thousands of virtual users. Suitable for both performance and stress testing.
- Locust: Python-based tool for managing large numbers of concurrent users. Tests are defined in Python with flexible configuration.
- Gatling: Scala-based tool popular in DevOps and high-load contexts. Supports API/HTTP and other protocols with rich scenario modeling.
- Artillery: Load-testing and monitoring tool with JavaScript and YAML scripting. Well-suited for API and microservice testing.
- ab (ApacheBench): Classic CLI that ships with Apache HTTP Server for quick performance checks.
- Siege: Simple but powerful tool to simulate concurrent requests with flexible scenarios.
Choosing a tool
- For quick load checks or to rapidly identify major performance issues, ab and Siege are excellent choices.
- For deeper analysis and complex scenarios involving large datasets or detailed user behavior simulation, tools like JMeter and Locust are recommended.